The first design iteration of the JDSS HPC cluster originated from our effort to construct a prototype for a multi-GPU, real-time data processing & visualization engine, proposed for the ARTS@CERN 2016 Collide Award. The arts programme of CERN is located at the European Laboratory for Particle Physics in Geneva. Its mission is to foster artistic engagement with CERN’s fundamental research.
At the time of our proposal drafting, readily available, non-academic HPC/GPU cluster and visualization environments suitable for production-grade, creative, and R&D-focused massive data exploration were scarce. We needed a cost-effective, multi-purpose environment capable of supporting the multi-tenant development and operational demands of our visualization engine. Previous research efforts had been hampered by a lack of local resources, suitable laboratory environments, and the prohibitive cost of cloud alternatives, all of which stifled innovation.
JDSS ARGUS Visualiation Cluster
CMS collision events at 7 TeV: candidate ZZ to 4e - Courtesy CERN
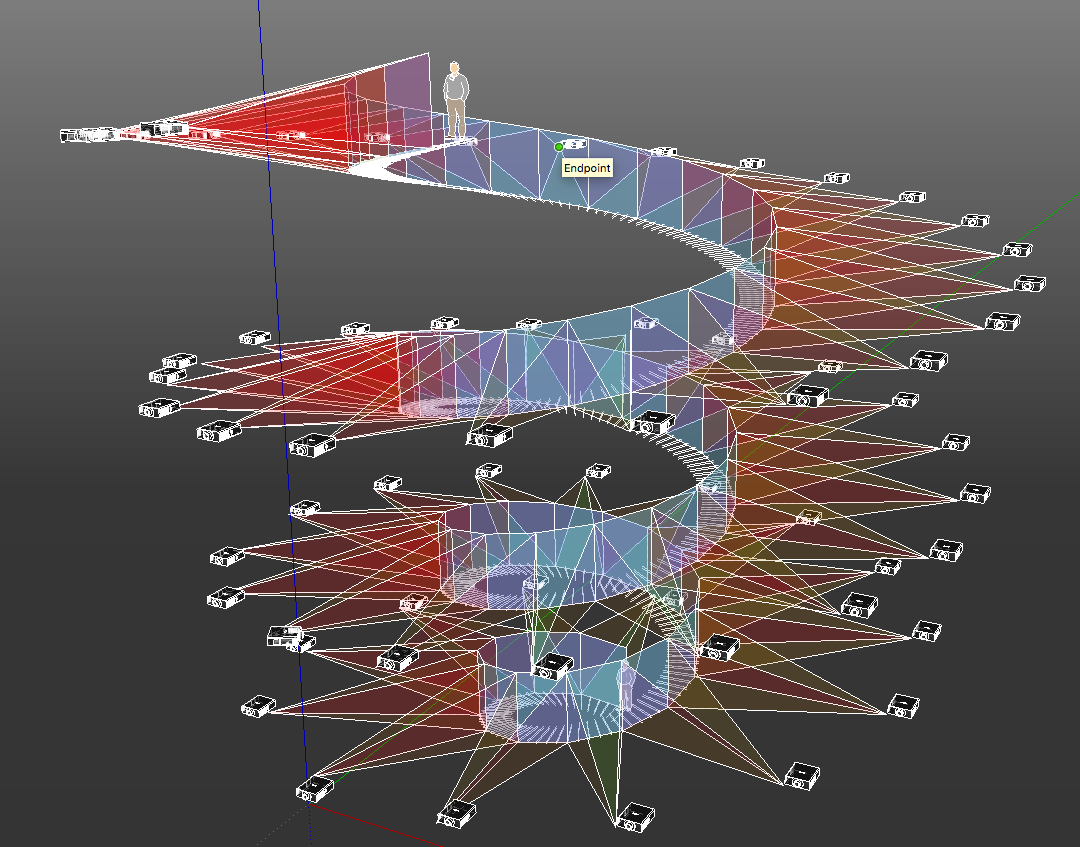
The architecture of our HPC cluster necessitated that we create a system that was capable of visualizing real-time streams of archived LHC particle data volumetrically. This also included designing the correlated systems for processing and rendering a subset of a the larger full CMS dataset (~300TB) of particle points and collision trajectories within a distributed 3D model, then distributing the output to an atomic clock synchronized array of 3-Chip DMD/DLP Laser stereoscopic projectors.
Joshua de Salis-Sophrin's patented method for 3D visual mapping using arrays of 3D stereoscopic projectors
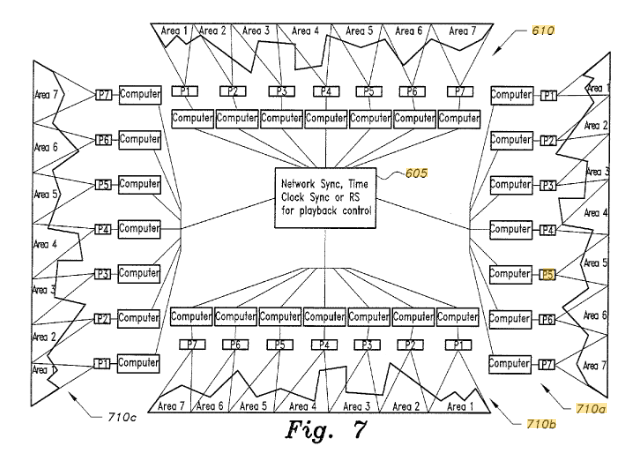
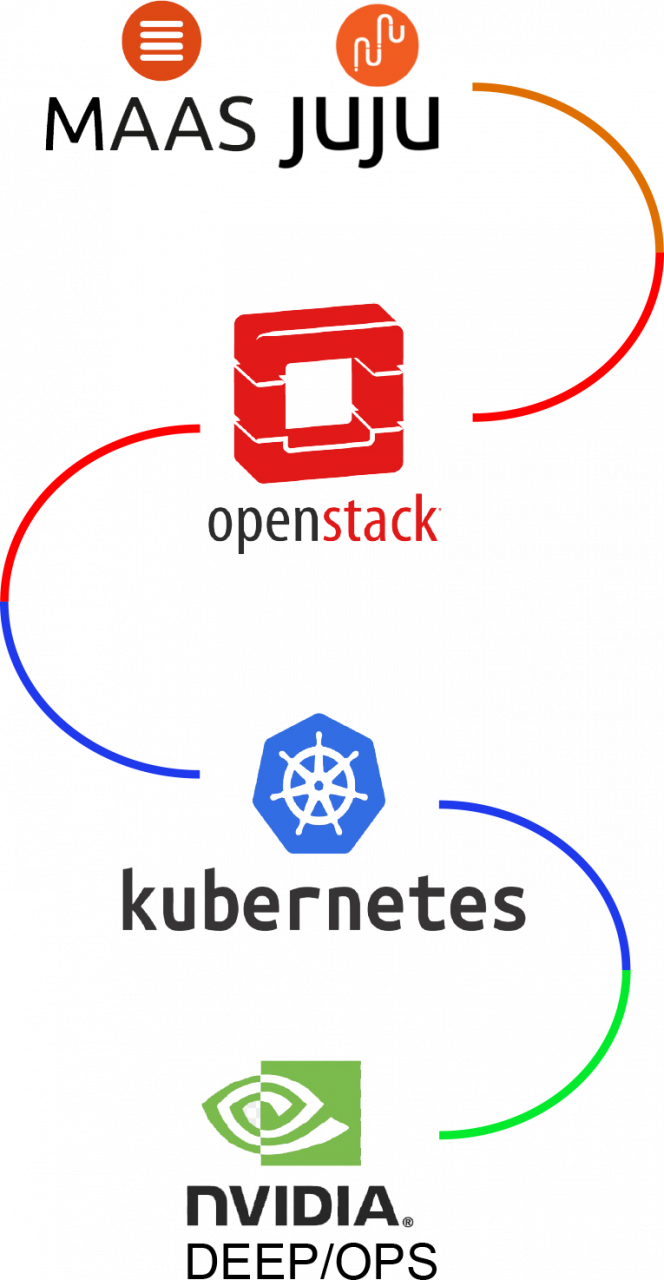
To maximize resource utilization, we investigated HPC methodologies used and explored by CERN’s engineering teams to manage massive amount of compute infrastructure, focusing on rapid OS re-provisioning and network reconfiguration for heterogeneous cluster mode switching. Existing tools fell short of our needs. Consequently, we adopted Canonical’s MaaS and Juju frameworks for hardware and software management due to their scalability, lifecycle management, testing utilities, and active open-source development, in which our team actively participated. Our goal was to deploy OpenStack on bare-metal nodes using Juju.
The MaaS/Juju/OpenStack combination was chosen for its enhanced functionality, security, and granular control. OpenStack facilitates physical and logical separation of projects and resources, enabling secure communication management between applications. The ability to combine virtualized instances and bare-metal resources within a multi-tenant environment, coupled with OpenStack’s built-in and integrated functionalities, created a more robust, scalable, and secure platform.
Following four years of R&D (2016-2020), JDSS successfully integrated MaaS, Juju, OpenStack, and Ironic to create a private, flexible HPC/GPU environment. An outflow of this effort is that we influence the development of the out of bound management (OOBM) of the DGX superpod network operating system specifications. This provisioning system evolved into, what is now known as Nvidia DeepOps. DeepOps provides us with a best practices framework for deploying GPU server clusters and sharing powerful nodes (like NVIDIA DGX Systems for running distributed containers of NVIDIA IndeX®), and can be adapted modularly to meet specific cluster needs.
3D Model of NVIDIA Superpod Architecture
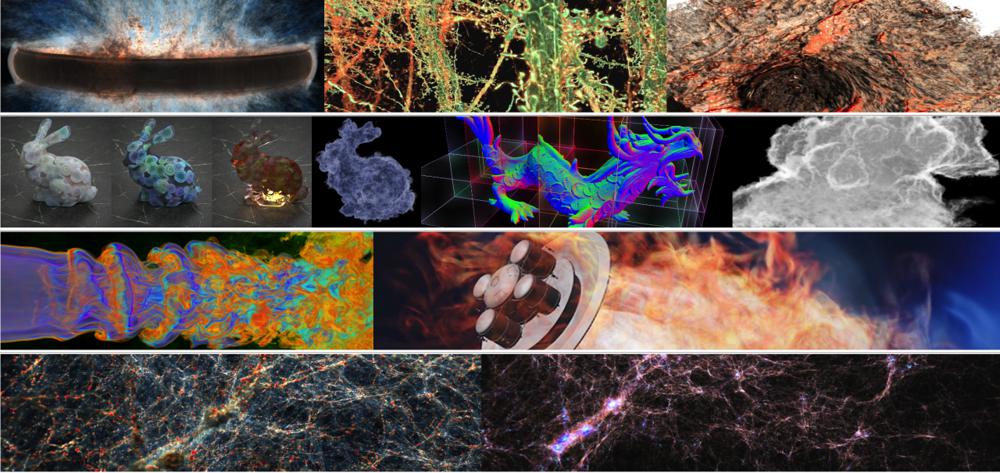
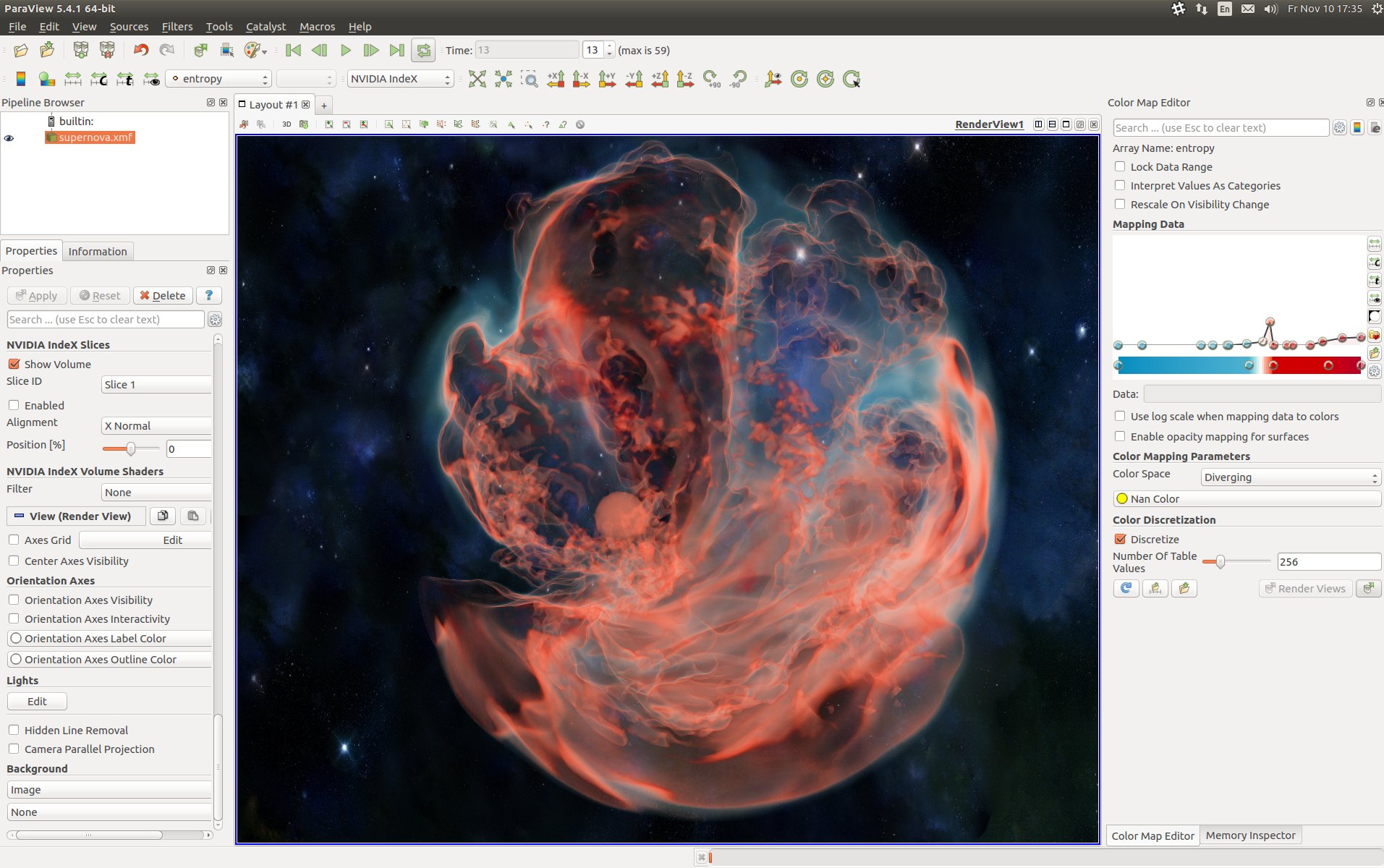
Astrophysics
Molecular
data visualizations using NVIDIA IndeX.
NVIDIA IndeX® is a 3D volumetric interactive visualization SDK that empowers scientists and researchers to visualize and interact with massive datasets in real time. Leveraging GPU clusters, IndeX enables scalable, real-time visualization and computation of multi-valued volumetric data, including embedded geometry.
Key features and benefits of IndeX include:
Interactive Exploration: Inspect volumes and modify transfer functions in real time.
Customizable Sampling: Reimplement sampling functions using CUDA.
Accelerated Insights: Derive detailed information, identify new features, and make discoveries faster.
Scalable Platform: Supports single and multi-GPU configurations, facilitating use in data centers (on-premise), the cloud, or on supercomputers.
Versatile Data Handling: Supports various volume dataset types (dense/sparse, regular/unstructured) for diverse domains like seismic, microscopy, astronomy, and cosmology.
Extensive Interfaces:
CUDA-based programmable XAC API for high-fidelity, custom visualizations.
Parallel processing and analysis of visualization data via user-implemented tasks scheduled across distributed GPUs.
Integration with user-defined deep learning inference operations.
Parallel data import of virtually any volume dataset format from any location.
IndeX integrates easily with existing visualization solutions like Kitware’s Paraview, and also supports development of new applications, visualization servers, cloud services, and globally accessible visualization apps. It provides a robust platform for creating real-time visualization solutions that deliver unique insights into complex scientific data.
ParaView is an open-source multiple-platform application for interactive, scientific visualization. It has a client–server architecture to facilitate remote visualization of datasets, and generates level of detail (LOD) models to maintain interactive frame rates for large datasets. It is an application built on top of the Visualization Toolkit (VTK) libraries. ParaView is an application designed for data parallelism on shared-memory or distributed-memory multicomputers and clusters. It can also be run as a single-computer application